Analysis
'What "Grounding" Really Means for Security AI — and What It Demands of Your Data'
The intelligence decides what your security AI can reason about, the grounding mechanism decides how, and the data decides whether it holds up against a threat that isn't in the record yet. Should we continue to scale legacy feed infrastructure horizontally, or is a different approach required for semi-autonomous, Agentic AI security systems that will augment our security teams?

In a previous post, The Rearview Mirror Problem, we argued that the kind of intelligence you ground a security AI system or agent on — forensic CTI versus continuous Internet Intelligence — determines what that system can and cannot reason about. Continuing from the data source, this post will go another level down into the functional and operational differences between grounding and training.
Although this is true for many components within its supporting architecture, grounding is not a single thing you can switch on from your cloud provider web interface; it’s a set of distinct engineering mechanisms, each with its own failure modes and, more importantly, its own hard requirements for the data feeding it. You can pick the right intelligence source but still build a structurally weak agent if the grounding mechanism and the data’s properties are mismatched. So before you’re tasked with implementing the next wave of “autonomous SOC” or SIEM deployments, it’s worth being precise about what grounding actually is, how it’s done, and why the data underneath it is the part that quietly decides whether any of it works.
What Grounding Actually Is
Grounding is the practice of tying a model’s outputs to verifiable, external facts rather than to its own parametric memory — the latter being the statistical residue of whatever it saw during training.
An ungrounded model answers from its weights based on the most probable continuation, given its training distribution, which is a remarkable thing for fluent language and even developing code, but a very dangerous thing for security decisions. The model has no native concept of whether the IP it just assessed is real, current, or related to anything it claims. It is confident either way.
A grounded model, by contrast, is constrained — at training time, at inference time, or both — to base its assertions on data it can point to within your own corpus of information. The practical difference is the difference between an agent that asserts and one that can show (or cite) its work.
In security contexts this distinction is not merely academic, and it has a specific, recurring failure signature we flagged in the last post: the agent that classifies novel infrastructure as benign not because it found evidence of safety, but because it found no evidence of known-bad. In the model’s reasoning, absence of a signal often becomes the presence of safety. Technically, this should be considered a hallucination (which we’ll define as a confident output unsupported by fact) and it is exactly the kind of error grounding exists to prevent. An agent that can only answer “I have no record of this” is far more useful to a human analyst than one that fills the gap with a fabricated all-clear. Unfortunately, we’re finding that either could happen.
So when we talk about grounding security AI, we are really asking two questions at once: (a) By what mechanism is the model’s reasoning anchored to fact, and (b) does the data behind that mechanism actually contain the facts the model needs? The rest of this post takes each in turn.
The Mechanisms of Grounding
There are many techniques for grounding, but I generally recommend that those building or implementing enterprise-scale agentic systems should use several of these in combination - especially in security and other high-stakes workflows, as each anchors the model in a different way and at a different point in the pipeline.
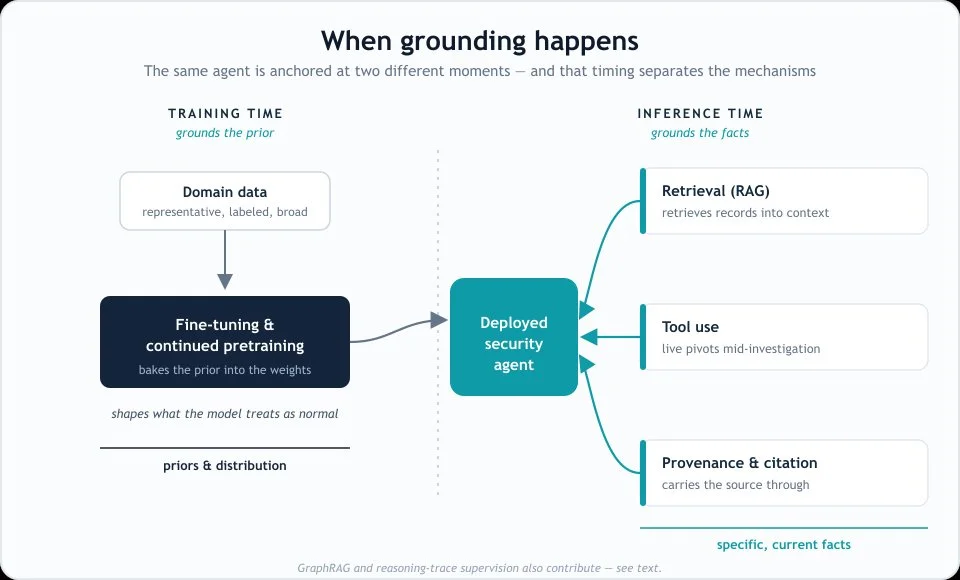
Diagram: Comparing when grounding happens - Training vs Inference time.
Retrieval-Augmented Generation (RAG). The most common mechanism and one that I’ve been talking about for over two years. Rather than relying on the model’s memory, a RAG system retrieves relevant records from an external corpus at inference time and places them into the model’s context, so the answer is generated over those records. RAG grounds specific facts at the moment of the query. Its quality is bounded entirely by the corpus: If the retrieval store is stale, incomplete, or flat, the model is grounded on stale, incomplete, flat facts — and seems just as confident in the model’s output.
Knowledge-graph & GraphRAG grounding. A variant where retrieval happens over a relational structure rather than a pile of documents. Instead of fetching the top-k text chunks that resemble the query, the system traverses entities and the edges between them — this IP, its domains, their certificates, the hosting neighbors, the historical record of those relationships. This matters in security specifically because infrastructure is relational. Flat retrieval can tell an agent what an indicator is; graph retrieval lets it reason about what an indicator is connected to, which is where novel-threat reasoning actually lives.
It should be noted that scaling GraphRAG (Graph Retrieval-Augmented Generation) to millions of documents requires overcoming heavy LLM extraction costs, slow retrieval times, and high embedding overheads. The best approach often requires combining hierarchical memory, lightweight extraction, and hybrid retrieval.
Fine-tuning & continued pretraining. Here the grounding is baked into the weights. You continue training the base model on domain-specific data so that its prior — its sense of what is normal, plausible, and worth attending to — reflects the security domain rather than the open web. A crucial distinction that separates the ML-literate from the marketing: fine-tuning grounds the model’s distribution and priors, not specific current facts. A fine-tuned model knows what C2 traffic tends to look like; it does not know that a particular IP is a live C2 server today. That is RAG’s and tool use’s job. Conflating the two is the most common tell that a “grounding strategy” hasn’t been thought through.
Tool use & function calling. This is an active, inference-time mechanism, often viewed as the live counterpart to RAG discussed above. Where retrieval grounds the model on records that already sit in a corpus, Tool Use grounds it on facts fetched on demand and mid-reasoning. Within the topic of a semi-automated SOC or SIEM capability, this would ideally resolve a domain, pull a certificate’s history, enumerate subnets, and fold each real result into the next step. This is the mechanism that makes autonomous investigation chains possible — pivoting from signal to signal at machine speed, the way a curious analyst would. It is also the most data- and resource-hungry of the mechanisms, because every pivot is a query against a backend that has to actually contain the next hop. An agent can only pivot as far as the data lets it.
In-context grounding with provenance & citation. Less a way of fetching facts than a layer over the mechanisms that do — RAG and tool use. It grounds not the answer but the answer’s traceability, carrying where each fact came from through to the output so the chain is auditable. In a human-in-the-loop workflow this is not a nicety; it is the entire basis of trust. An escalation a senior analyst can trace back to its source evidence is actionable, while an unsourced verdict from a black box is just more noise to triage.
Reasoning-trace & process supervision. A more recent mechanism that grounds the path rather than only the answer. Instead of supervising whether the final classification was right, you supervise whether each intermediate step of reasoning was sound — modeled on curated trajectories of good multi-step investigation. This is what hardens an agent against plausible-but-wrong reasoning chains, and it requires a fundamentally different kind of training data: not labeled endpoints, but labeled trajectories.
The takeaway here is that all six of these mechanisms are complementary, and each makes a different demand on the data types, structure, and storage. This finally brings us to the part that actually determines outcomes.
The Data Requirements
Every mechanism above is only as good as the data behind it. You can implement textbook RAG, a clean knowledge graph, and elegant tool use, and still ship a structurally blind agent if the underlying data lacks the properties those mechanisms assume. In our high-level opinion, there are several features that are definite requirements for the data being used within security workflows.
Freshness. Malicious IPs rotate in hours, phishing domains go dark inside a day, and C2 infrastructure migrates constantly. A retrieval corpus or training set that lags reality by weeks grounds the agent in a world that no longer exists because it builds strong pattern recognition for infrastructure that adversaries have already abandoned. Any grounding store feeding a security agent has to be refreshed on a cadence that outpaces indicator decay, or the grounding is grounding on a ghost.
Native relational structure. GraphRAG, tool-use pivots, and infrastructure reasoning all assume the data is a graph. For example, this would assume that an IP record arrives already connected to its domains, certificates, ASN, hosting neighbors, and the history of those relationships. If your data is a flat list of indicators, no amount of clever retrieval reconstructs the edges that were never captured. Despite what many of the legacy providers in our space try to claim as they struggle to pivot into an AI-friendly offering: Relational depth cannot be bolted on after the fact - it has to be the structure of the data from the start.
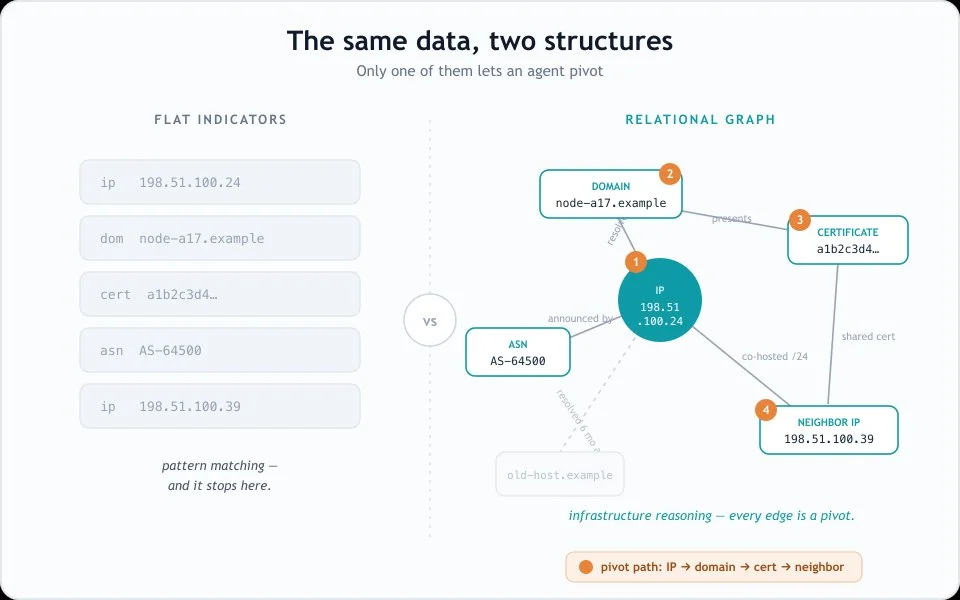
Diagram: Flat vs. Graph retrieval working in a security workflow.
Temporal provenance. A domain that looked unremarkable six months ago may resolve to malicious infrastructure today; a “new” certificate pattern may be structurally identical to one used against you last year. Grounding an agent in current state alone strips out exactly the historical dimension that lets it reason about provenance. The data needs to carry its own history, and it needs to carry where each fact came from so the human at the end of the chain can verify it.
Coverage breadth & low sampling bias. Every dataset reflects the sensor footprint of whoever produced it. Because of this, training or grounding on a narrow source means the agent inherits its blind spots as confident certainty — systematic under-representation of geographies, hosting environments, and attack categories outside the original visibility. Grounding data has to approach the problem from comprehensive observation, not from one vendor’s keyhole.
Label quality & ground truth. Fine-tuning and supervised detection are only as good as their labels. Mislabeled, ambiguous, or thinly-sampled categories produce models that are precisely wrong. Labeled C2 and beaconing behavior, drawn from real adversary activity rather than synthetic approximations of it, is what lets an agent learn the subtle TTPs that signatures miss.
A baseline of normal. This is the requirement most CTI-grounded systems lack entirely, and it is the antidote to the “no known-bad, therefore benign” hallucination discussed above. If the data maps what normal internet infrastructure looks like (ex. hosting patterns, certificate behaviors, registration timing), the agent can distinguish “unknown and consistent with normal” from “unknown and anomalous.” Grounding on a blocklist can never produce that distinction; grounding on a baseline can. Remember that the negative space matters as much as the known-bad.
Volume & pre-correlation deep enough to pivot. Autonomous investigation only works if every hop in the chain has somewhere to go: IP to domain, domain to certificate, certificate to co-hosted asset, asset to hosting neighbor, and on. That requires enormous volumes of pre-correlated relational data sitting behind the agent’s tools. Without it, the agent pivots once, finds nothing, and terminates — which looks exactly like a clean investigation and is in fact a blind one.
Synthetic augmentation for the rare & the unseen. The highest-stakes scenarios are, by definition, the least represented in any real dataset. A synthetic fusion layer — enriching raw telemetry with contextual signals, entity resolution, temporal correlations, and recorded attack scenarios — fills the long tail so agents see enough variations of rare events to reason about them when they appear for real.
Read that list back against the mechanisms and the pattern is hard to miss: RAG wants freshness, GraphRAG and tool use want relational depth and pre-correlation, fine-tuning wants labels and coverage, provenance grounding wants history, and the whole anti-hallucination project wants a baseline of normal. These are not nice-to-haves layered on top - they are the properties that decide whether the grounding mechanism does anything at all.
Grounding Is What Lets AI Augment a Human Team
It’s worth being clear about why all of this engineering matters, because the goal with this article and the founding of Dendrite as a whole is not a fully autonomous SOC / SIEM combo that replaces analysts. The goal actually worth building toward is augmentation: AI that makes a stretched security team meaningfully more capable and accurate, with less fatigue, so that they can take the initiative with other security tasking.
Augmentation only works on a foundation of trust, and trust is upstream of grounding. A senior analyst will act on an agent’s escalation when they can trace it back to source evidence — this certificate, that hosting relationship, this historical overlap — and dismiss it just as quickly when the chain doesn’t hold. An unsourced verdict, however confident, is not a force multiplier; it’s another alert to investigate. Provenance-grounded output is what converts an agent from a noise generator into a colleague.
The effect on the team’s shape is just as important. When the relational graph is pre-correlated and the agent’s reasoning is auditable, a junior analyst can navigate infrastructure — C2 pre-correlated to groups, their TTPs, their broader topology — that they could not have mapped manually in any reasonable timeframe. Grounding doesn’t just make the AI better; it raises the floor of what every analyst on the team can do, and frees the senior people to spend their judgment where judgment is actually required.
That is the real argument for taking grounding seriously. Not because it makes a demo more impressive, but because a well-grounded agent extends what a human team can observe and defend against, while a poorly-grounded one quietly narrows it and hides the narrowing behind fluent, confident language.
The Bottom Line
Grounding is not a switch. It is a set of mechanisms — retrieval, graph traversal, fine-tuning, tool use, provenance, reasoning supervision — and each one imposes specific, non-negotiable requirements on the data underneath it. Freshness, relational structure, temporal provenance, broad coverage, clean labels, a baseline of normal, and pre-correlation deep enough to sustain a real investigation are not features you add later. They are the substrate that determines whether any grounding mechanism produces a capable agent or a confident, blind one.
Also, remember that the intelligence source decides what your security AI can reason about. The grounding mechanism decides how. And the properties of the data decide whether the whole thing holds up the first time it meets a threat that isn’t in the record yet.
Unfortunately, despite the marketing claims and financial investment in the AI security space, we’re seeing that the vast majority of legacy “feeds & speeds” and security data-source providers are simply trying to adapt or rebrand their existing data without much consideration for the mechanisms and requirements listed above. As always, be cautious in meetings with these reps because it is likely their core collection technologies and methodologies both lack the pedigree required to ground your security-focused AI agents.
Closing Thoughts & Going Forward
Recognition of the challenges discussed above is at the very core of Dendrite’s inception and what drives us to continue creating proprietary datasets and methodologies. As most readers may notice and to put the problem statement plainly: the data requirements for effective agentic AI security solutions - ones that truly augment skilled human security teams - either cannot or are not met by the majority of legacy security data providers. This has been a huge motivator for our team and advisors.
If my schedule permits, I would like to build and release architectural designs for deploying the grounding mechanisms discussed above, complete with specific tech recommendations and provisioning requirements. Either way, this will definitely appear in the Enterprise deployment documentation. Regardless of this, my upcoming posts will continue to focus on functional and operational gaps suffered by the industry at large, specifically within AI & ML security workflows. We also have some walk-through videos on tool, platform, and data usage in the works, as well as a 5th data source nearing completion.
As always, I hope that you will feel free to reach out via Dendrite X or LinkedIn if you have any questions, notes, or just want to collab.